CPU流水线技术
CPU流水线技术
不同指令的执行时间不同,如果让所有指令都能在一个时钟周期内完成,那就我们只能将时钟周期设置为指令执行时间的最大值,这样最大组合逻辑延迟决定了CPU频率上限,一般CPU的性能与CPU频率呈正相关,因此,降低组合逻辑的延迟能够提升CPU性能。方法包括划分较小的组合逻辑和流水线设计。
CPU的流水线设计
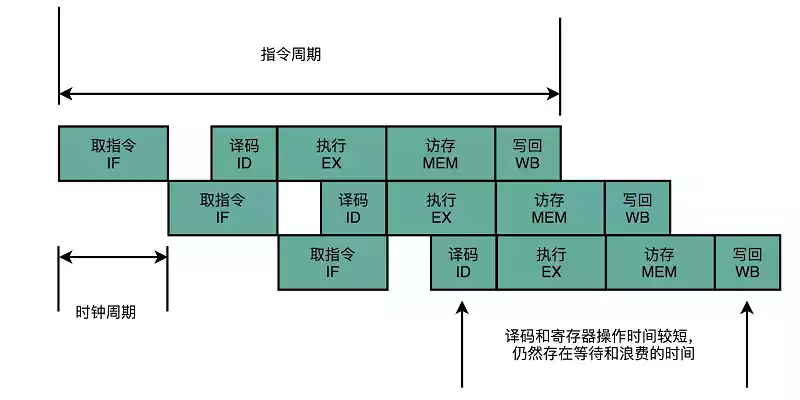
- 取指令(IF):从存储器取指令
- 指令译码(ID):产生指令执行的控制信号和操作数
- 执行(EX):执行部件根据指令完成运算
- 访存(MEM):从存储器读取或写入数据
- 写回(WB):将运算结果写回存储器
CPU提供了最长的公共流水线,但并非所有指令都能利用各个阶段,而且实际上流水线划分不一定均匀,考虑将操作时间长的指令深度划分……虽然流水线设计不能减少单指令执行的“延时”,但是提高了CPU的吞吐率。
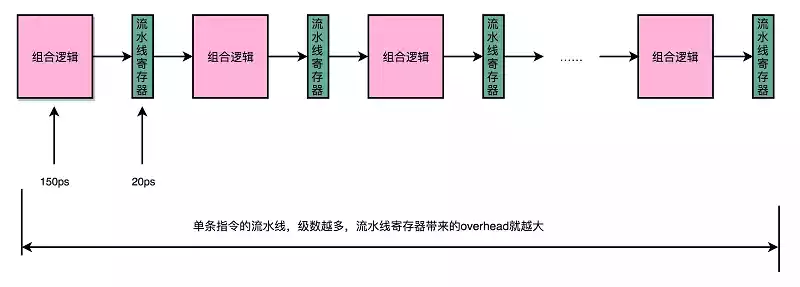
超长流水线的性能瓶颈
为了保持段间数据,需要设置流水线寄存器,然后再下一个时钟周期交给下一流水线级处理,每增加一级流水线,就多一次写入寄存器的时间。
流水线冒险
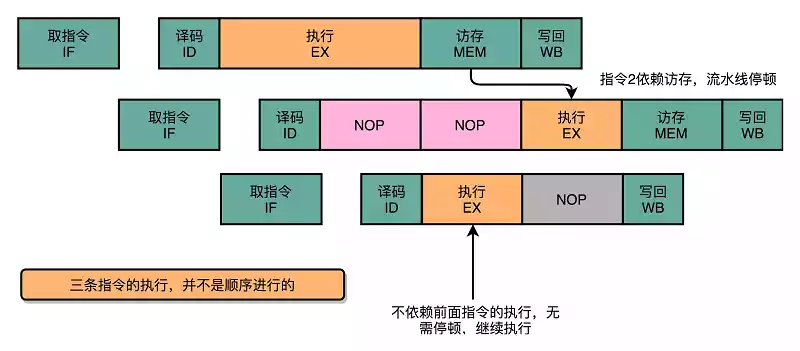
将指令拆解为流水线并行执行,会遇到依赖阻塞问题,如果后续指令运行依赖前序指令的运行结果,那么后续指引起流水线的阻塞。
结构冒险
同一部件被不同指令使用,由硬件资源竞争造成的冒险。
冒险消除
- 增加多个部件或多个通道,实现寄存器堆同时读写
- 借助Cache
类似于机械键盘“全键无冲”的解决方案,本质上就是增加资源。对于访问内存数据和取指令的冲突,最直观的解决方案就是把内存分成两部分,让他们有各自的地址译码器,分别是存放指令的程序内存和存放数据的数据内存
将内存拆成两部分的解决方案称作哈佛结构,传统的冯·诺依曼结构称作普林斯顿结构。
我们今天使用的CPU依然是冯·诺依曼结构。
现代的CPU没有在内存层面进行对应的拆分,但是在CPU内部的高速缓存部分进行了区分,把高速缓存分成了指令缓存和数据缓存。
数据冒险
后续指令执行时前序指令的结果还未产生(结果未存储)。
冒险消除(数据的依赖关系)
- 加入空操作
- 流水线停顿(流水线冒泡):插入
NOP,等前序指令结果产生(编译器优化) - 操作数前推(操作数旁路):不必等到前一个指令写回,执行的结果直接传给下一个指令的ALU。可以单独使用也可以与流水线冒泡一起使用。
类比:流水线停顿像游泳接力,前一个游到头下一个开始游;操作数前推像短跑接力,下一个运动员可以抢跑。
控制冒险
指令跳转带来的指令顺序改变。
冒险消除
- 延迟槽(delay slot):,接下来的一个或多个指令槽填充一些不影响当前操作结果(与分支无关)的指令,等待分支指令的PC值
- 乱序执行:重排指令,提前执行与分支无关的指令(编译器优化)
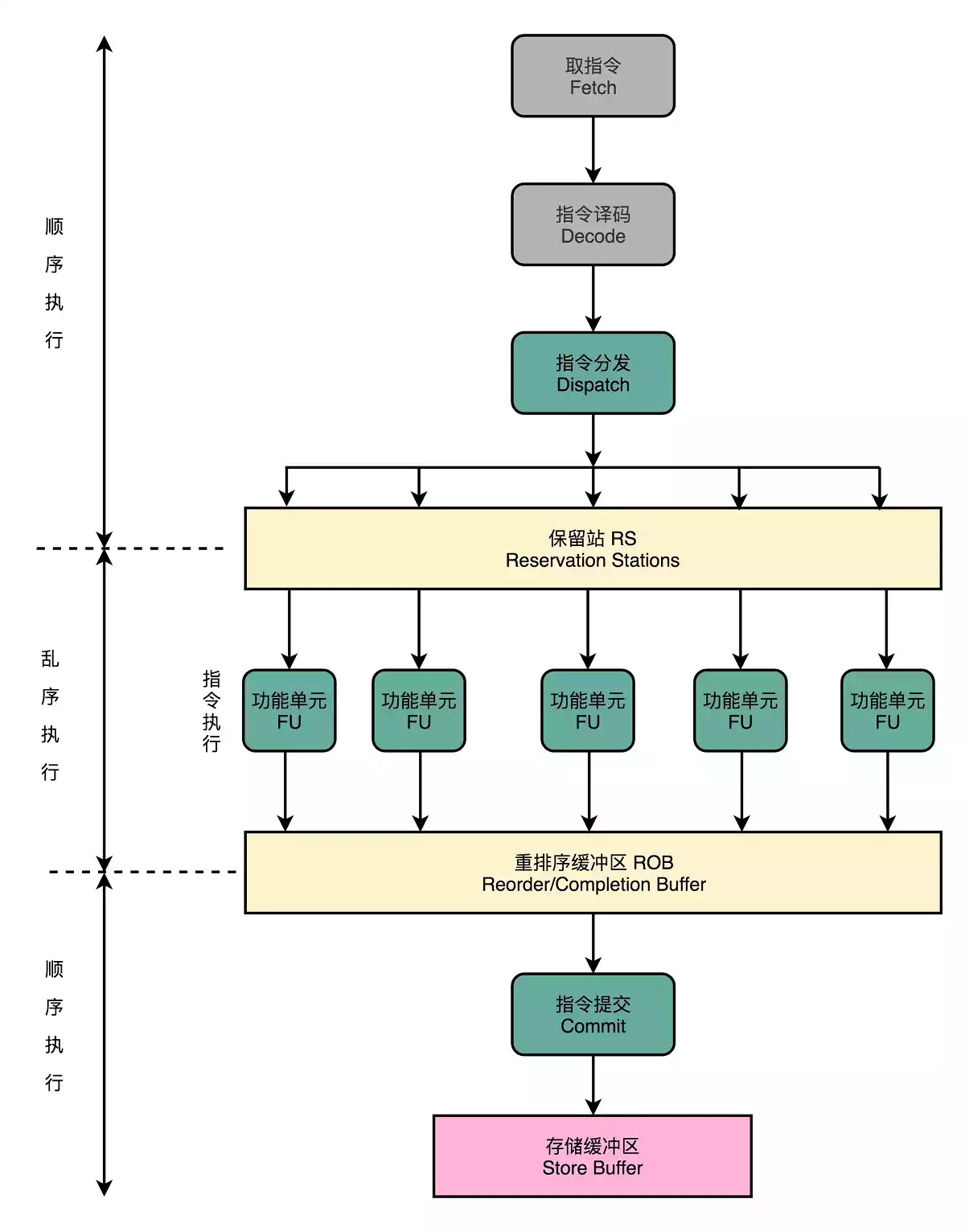
CPU的线性池
现代CPU的访问速度比访问主存要快很多,如果采用完全顺序执行,很多时间都会浪费在前面指令等待获取内存数据。
在取指令和指令译码过程中,乱序执行的CPU和其它流水线架构的CPU一样,会顺序执行;指令译码完成后,CPU不会直接进行指令执行,而是进行一次指令分发,分发到保留站;这些指令不会立刻执行,而是等待它们所依赖的数据传递给他们;
依赖数据到齐之后,指令交给功能单元,可以并行执行;指令执行结束后,结果存放到重排序缓冲区,CPU根据指令的顺序对计算结果重新排序。
- 分支预测:预取数据(编译器优化),可能出现错误
- 静态分支预测:“假设分支不发生”,按照顺序把指令往下执行。如果预测失败,就把后面已经取出指令已经执行的部分给丢弃掉(Zap/Flush)
- 动态分支预测:引入状态机……(
比特饱和计数)
预测
在jmp指令发生的时候,CPU可能会跳转去执行其它指令,jmp后面的一条指令是否应该顺序加载,在流水线里面取指令的时候,我们没办法知道。要等jmp执行之后,更新了PC寄存器我们才知道执行下一条指令还是跳转到另一个内存地址,这种为了确保得到正确的指令而不得不等待延迟的情况就是控制冒险。
缩短分支延迟
条件跳转指令其实进行了两种电路操作
- 条件比较,根据输入指令的opcode确认条件码寄存器
- 实际跳转,要跳转的地址信息写入PC寄存器
无论是 opcode,还是对应的条件码寄存器,还是我们跳转的地址,都是在指令译码的阶段就能获得的。而对应的条件码比较的电路,只要是简单的逻辑门电路就可以了,并不需要一个完整而复杂的 ALU。
因此,可以讲条件判断、地址跳转都提前移到指令译码阶段进行,同时在CPU里面设计对应的旁路,在指令译码阶段就提供对应的判断比较的电路。
思想上和操作数前推类似,在硬件电路层面,把一些计算结果更早地反馈到流水线中,反馈的更快,后面的指令需要等待的时间就变短。