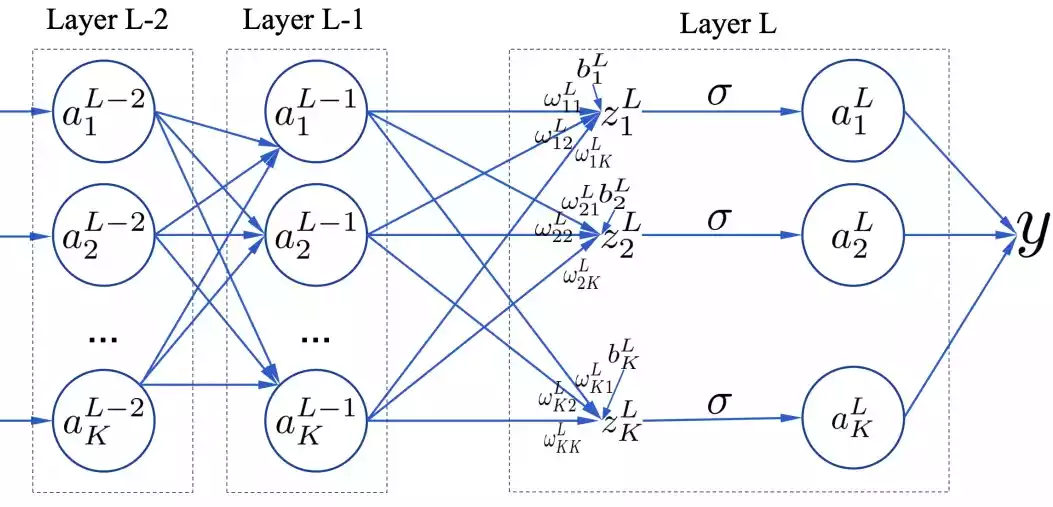
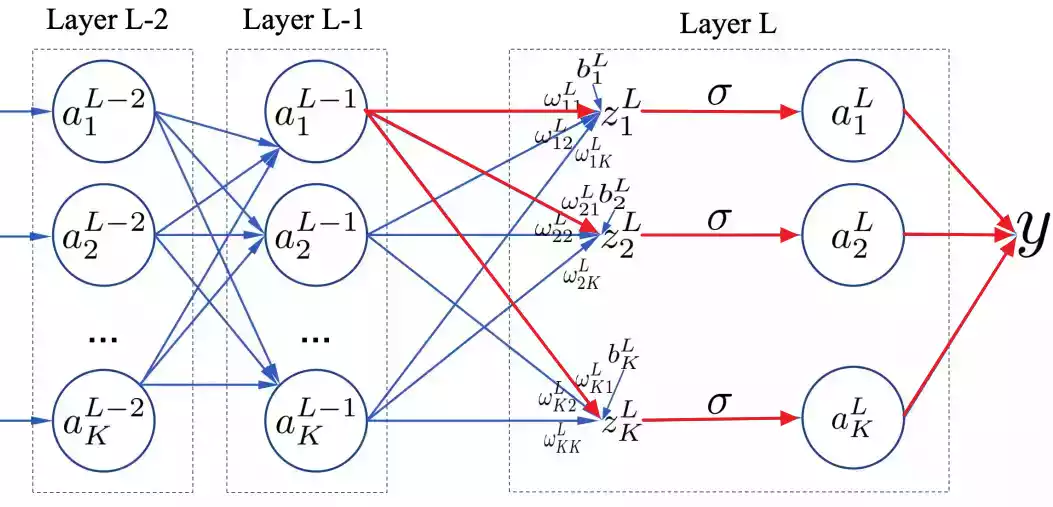
defbackprop(self, x, y): """Return a tuple ``(nabla_b, nabla_w)`` representing the gradient for the cost function C_x. ``nabla_b`` and ``nabla_w`` are layer-by-layer lists of numpy arrays, similar to ``self.biases`` and ``self.weights``.""" nabla_b = [np.zeros(b.shape) for b in self.biases] nabla_w = [np.zeros(w.shape) for w in self.weights] # 前向传播 activation = x activations = [x] # list to store all the activations, layer by layer zs = [] # list to store all the z vectors, layer by layer for b, w inzip(self.biases, self.weights): z = np.dot(w, activation)+b zs.append(z) activation = sigmoid(z) activations.append(activation) # 反向传播 delta = self.cost_derivative(activations[-1], y) * \ sigmoid_prime(zs[-1]) nabla_b[-1] = delta nabla_w[-1] = np.dot(delta, activations[-2].transpose()) # Note that the variable l in the loop below is used a little # differently to the notation in Chapter 2 of the book. Here, # l = 1 means the last layer of neurons, l = 2 is the # second-last layer, and so on. It's a renumbering of the # scheme in the book, used here to take advantage of the fact # that Python can use negative indices in lists. for l in xrange(2, self.num_layers): z = zs[-l] sp = sigmoid_prime(z) delta = np.dot(self.weights[-l+1].transpose(), delta) * sp nabla_b[-l] = delta nabla_w[-l] = np.dot(delta, activations[-l-1].transpose()) return (nabla_b, nabla_w)